서문. 레디스가 뭔가요?
백엔드 개발자는 데이터베이스와 뗄래야 뗄 수 없는 관계라고 생각합니다. DB 관리에 불철주야 몰두하시는 DBA님들이 계시지만, 내 문제상황에 걸맞는 DB어플리케이션을 선택하고 개발하는 것은 백엔드 개발자의 몫 아닐런지요.
30년이 넘는 시간동안 백엔드 개발자에게 사랑받고 있는 RDBMS(Relational DataBase Management System)가 사랑받고 있지만, 대용량 데이터 저장, 비정형 데이터 저장, 빠른 응답시간 등의 새로운 요구사항에 기존 RDBMS만으론 대응하기 어려울 때가 있습니다.
그럴 때 기존 RDBMS와 차별적인 강점을 갖춘 데이터베이스 관리 프로그램 들, NoSql을 찾게 됩니다.
NoSql?
NoSql은 기존 RDBMS 방식을 탈피한 데이터베이스를 의미합니다. 과거 스터디 때 정리한 글을 첨부합니다. 
NoSql의 종류
NoSql은 RDBMS가 아님 을 의미하므로, 여러 종류가 있습니다.
•
서로 연관된 그래프 형식의 데이터를 저장할 수 있는 Graph Store
•
Row가 아닌 Column 위주로 데이터를 저장하는 Column Store
•
비정형 대량 데이터를 저장하기 위한 Document Store
•
메모리 기반으로 빠르게 데이터를 읽어올 수 있는 Key-Value Store
Redis
이 중 레디스는 세계에서 가장 인기있는 Key-Value Store 중 하나입니다.
Remote Dictionary Server의 약자로, 원격 Dictinary 자료구조 서버 라는 직관적인 이름을 가지고 있습니다.

Key로 올 수 있는 자료형은 기본적으로 String이지만, Value는 다양한 타입을 지원합니다.
메모리 기반의 데이터베이스이기 때문에, Disk를 기반으로 하는 RDBMS보다 read가 빠릅니다.
잠깐! RDBMS도 쿼리를 통해 조회해오면, 메모리에 존재하는 Buffered Cache를 이용한다고 알고 있어요. (= Cache Hit) Buffered Cache를 활용할 때의 RDBMS와 레디스는 조회 시간 차이가 없나요? 경험상 RDBMS에서 동일 select문 n회 조회할 때(cache hit)와 Redis의 조회 속도를 비교해보면 Redis가 더 빠른데요, 과거 AWS에서 monggo DB 담당하시는 이덕현 개발자님이 세미나에서 “RDBMS는 데이터의 직렬화, 역직렬화 과정이 있기 때문에 레디스보다 더 느린 것 같다"고 추론했다는 언급을 하신 적 있습니다.자바 해쉬맵과의 비교
저는 java로 개발을 배우고 지금도 java로 먹고 살고 있는 개발자기 때문에, 레디스의 개념을 처음 접했을 때 “앵? 이거 완전 자바 HashMap 아니냐?”라는 생각을 한 적이 있습니다.
둘 다 key-value 기반이고, 메모리 베이스며, 원하는 value를 제가 원하는 표현방식으로 넣을 수 있습니다.
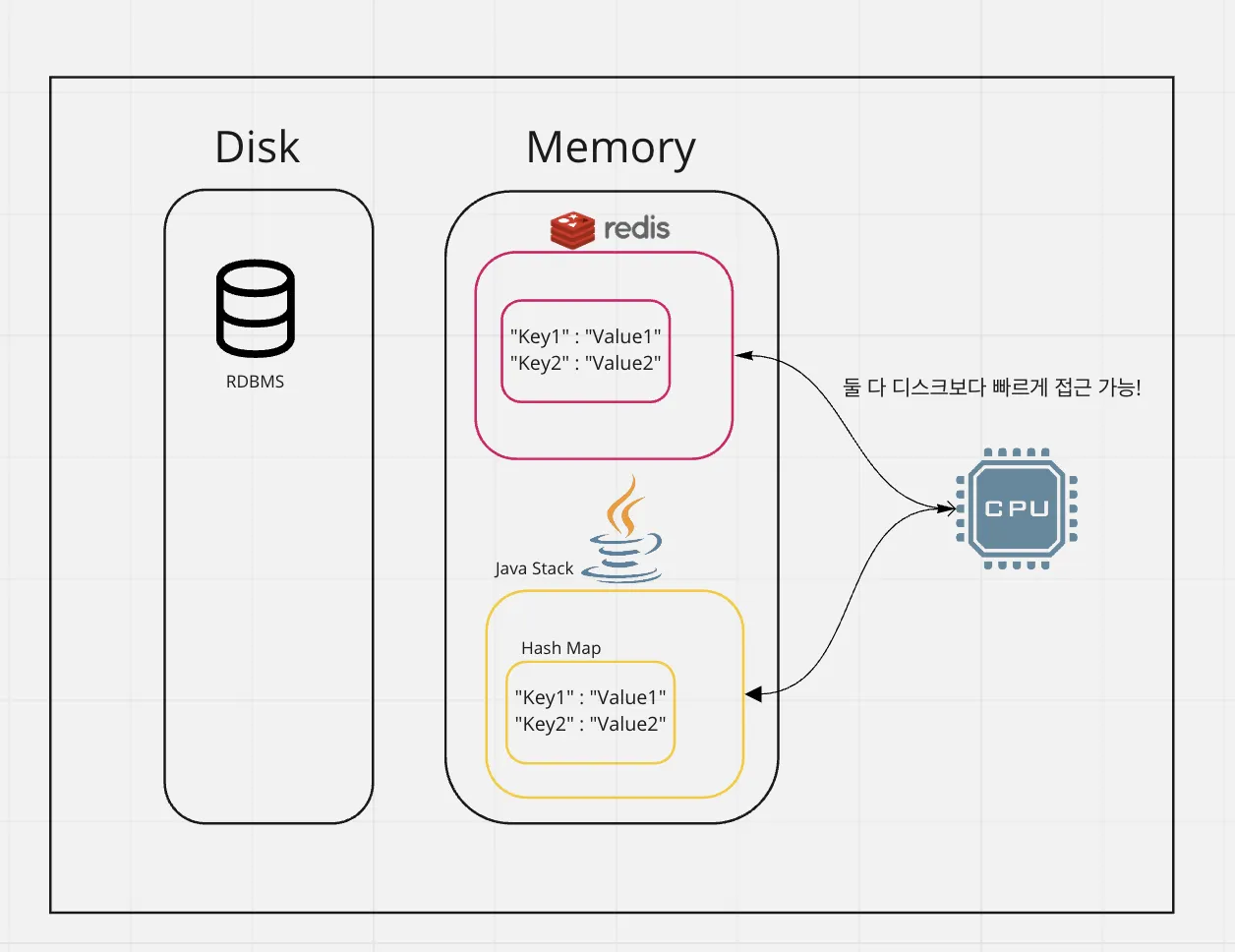
1대의 서버에서 굳이 레디스를 쓸 필요가 있을까?
그러면 어플리케이션 개발할 때 그냥 HashMap 쓰면 되지, 굳이 Java - Redis 연동 클라이언트를 써가며 Redis를 활용할 필요가 있을까요?
서버가 1대 있다는 가정에선 Redis의 장점이 크게 보이지 않지만, 분산 환경을 대입하면 장점이 보입니다.
분산 환경에서의 장점
유저 요청이 크게 늘어나 서버를 몇 대 증설하였지만, 동일한 해쉬맵 데이터를 참조해야할 상황이 있다고 가정합니다.
이 때 원격 프로세스간에 동일한 해쉬맵 데이터를 참조해야 할 때, 분산환경에선 원격 프로세스간 데이터를 동기화 하기 어렵습니다.
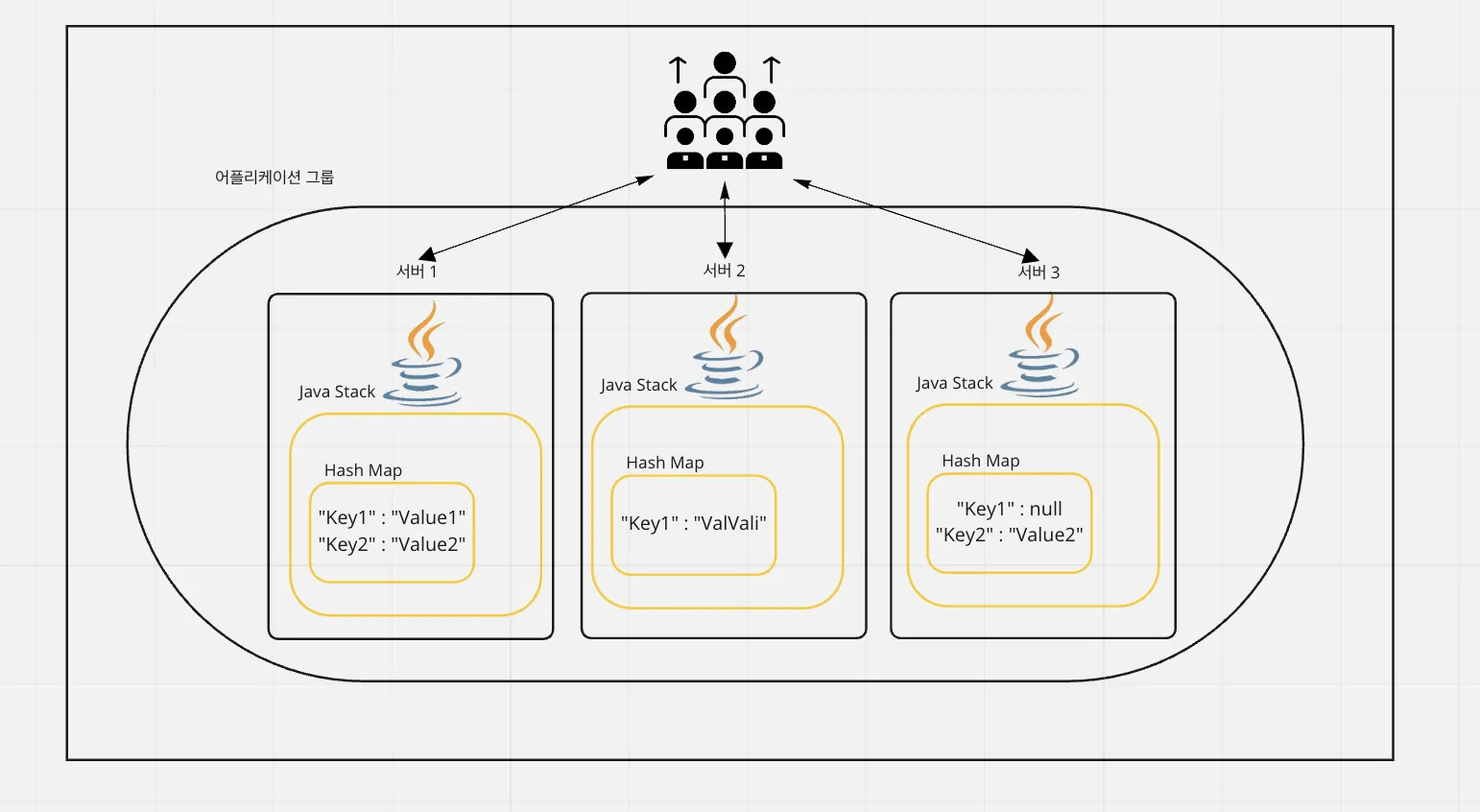
원격 프로세스간의 데이터를 일치시키기 어렵다.
이 때 별도의 레디스 서버를 구성하고, 해당 레디스에서 값을 꺼내 쓴다면 메모리 기반 데이터 구조의 빠른 응답성을 확보함과 동시에 데이터 불일치 문제를 해결할 수 있습니다.
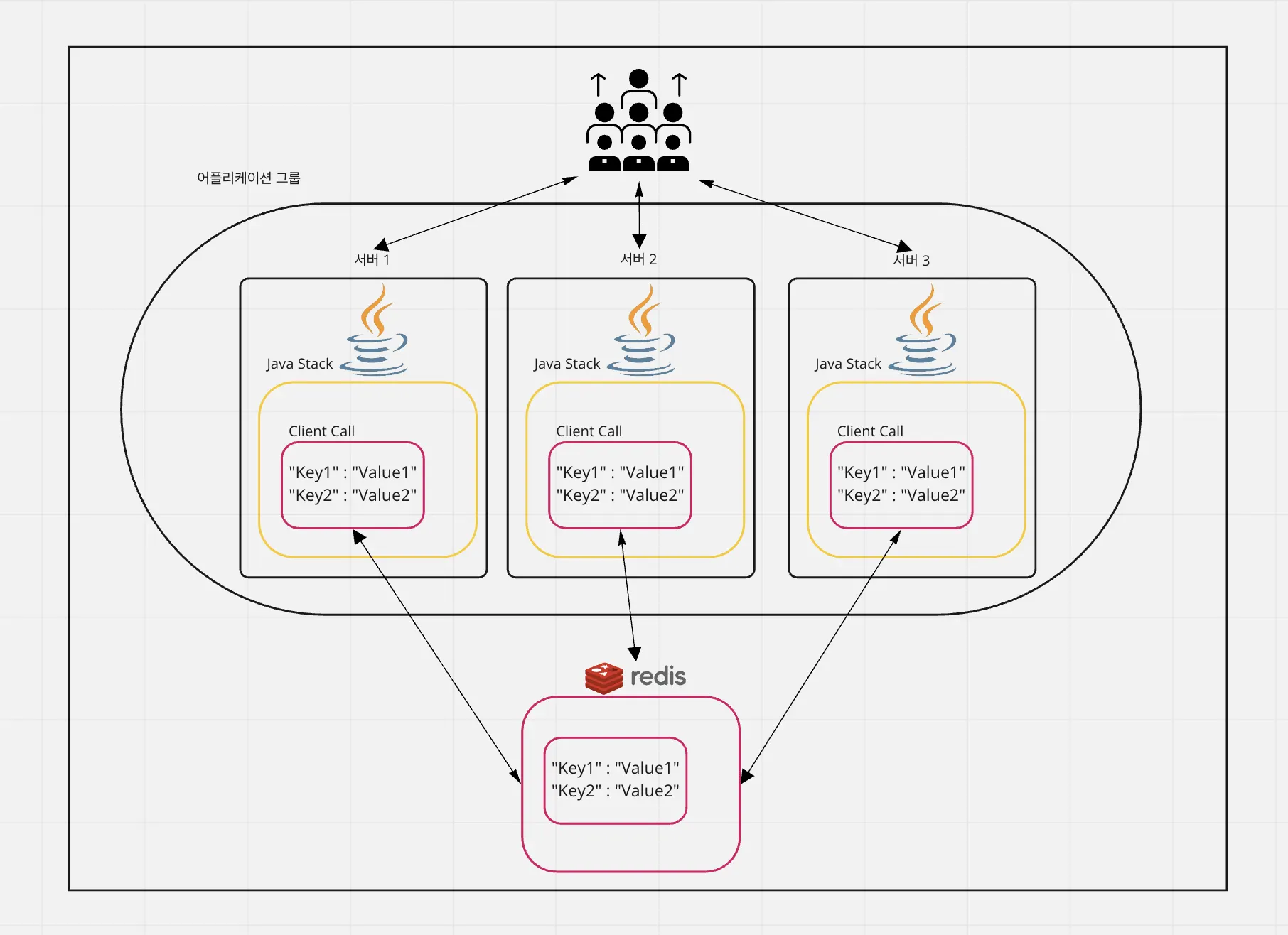
레디스에서 Key-Value 데이터 구조를 별도로 관리한다.
DBMS로서의 장점
또한 어플리케이션을 종료하면 휘발되어 사라져버리는 HashMap과 달리, Redis는 다양한 영속성(디스크에 백업) 옵션을 제공합니다.

영속성 외에도 범용 프로그래밍 언어인 Java에서 다루기 까다로운 여러 기능도 DBMS로써 갖추고 있습니다.
•
TTL 설정 → 일정 시간이 지나면 데이터 삭제, 용량이 작은 메모리의 효율적 관리
•
분산 데이터 저장소 구성 → Redis Cluster 등 분산환경에서 안정적인 데이터 관리 가능
•
보안체계 → 악성 스크립트 공격으로 부터 안전 보장, TLS 지원
본문. 레디스 설치하기 + 레디스 튜토리얼
레디스 공식 홈페이지 getting-started에서 친절하게 설명해주고 있습니다.

Mac에서 설치하기
# brew가 없다면 https://brew.sh/
$ brew --version
$ brew install redis
Bash
복사
설치가 완료되었다면, foreground에서 Redis Server 을 실행시켜 봅니다.
$ redis-server
Bash
복사
foreground 실행
옵션을 주지 않고 부팅했을 때 redis의 default 포트는 6379포트입니다. redis를 설치할 때 함께 설치되는 redis-cli를 통해 접속해 봅시다.
별도의 terminal 탭에서 redis-cli를 이용해 접근해 봅시다.
$ redis-cli
Bash
복사
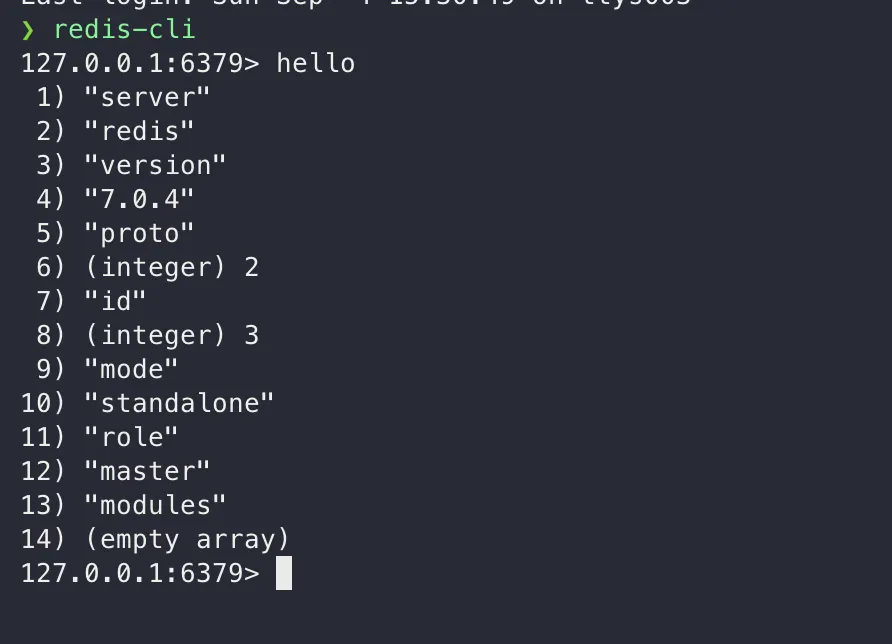
hello로 인사하니 의외의 값들이 세팅되어 있다
CLI 접근에 성공하였으니 본격적으로 튜토리얼을 시작해보겠습니다.
key를 잡을 때 주의할 점
레디스 튜토리얼에선 적절한 Key 값에 대해 다음과 같이 충고합니다.
•
Key의 최대 길이는 512MB이다. (value도 마찬가지)
•
매우 긴 키는 좋지 않다. 예컨데 1MB 길이의 키는 메모리 관리 측면 뿐만 아니라 키를 조회할 때 고비용의 키 비교 로직을 실행해야 할 수 있기 때문에 나쁜 생각이다. 키 값이 너무 길다면 차라리 SHA-1 등으로 해싱하라.
◦
redis를 쓰는 주요한 목적이 빠른 응답속도를 보장받고자 함임을 생각해보면… 성능을 악화시킬 수 있는 요소는 최대한 배제하는 게 좋다고 생각합니다.
•
매우 짧은 키 또한 좋은 생각이 아니다. user:1000:followers 대신 u1000flw 로 사용하는 것은, 메모리상 이득은 작고 가독성은 해치는 것이다. (key가 차지하는 공간은 value에 비해 작기 때문에) 비록 작은 메모리상 이득은 있지만, 가독성과 메모리 효율사이의 적당한 균형을 찾아라.
•
고정된 스키마를 활용해라. object-type:id 형식은 좋은 생각이다. ex) user:1000 만약 여러 단어를 조합해야 할 일이 있으면, .이나 - 가 주로 활용된다.
ex) comment:4321:reply.to , comment:4321:reply-to
String 유형
문자열을 value로 사용하는 가장 단순한 유형입니다. 문자열을 value로 사용하므로, html 문자열을 캐시하는 식의 활용 방법이 있습니다.
SET
값을 세팅할 때는 SET을 사용합니다.
SET [keyName] [value] [값이 이미 있으면 실패 : nx, 값이 이미 있을 때만 성공 : xx]
Bash
복사
GET
값을 찾아 올 때는 GET을 사용합니다.
GET [keyName]
Bash
복사
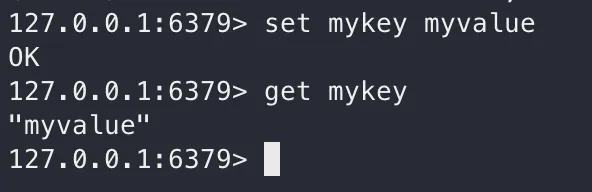
Strings set, get
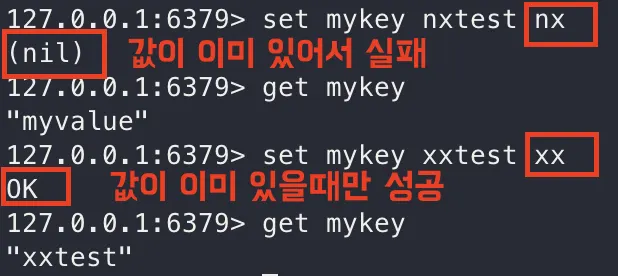
set nx, set xx 옵션
INCR, DECR
값이 정수인 경우, INCR과 DECR (increment, decrement) 명령어를 활용할 수 있습니다. (정수가 아니라면 오류)
INCR [keyName]
DECR [keyName]
Bash
복사
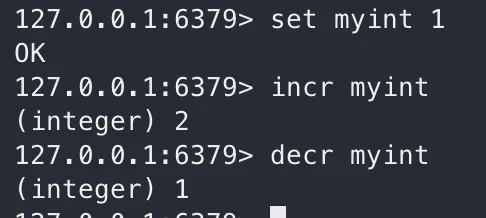
incr, decr
MSET
여러 key를 동시에 세팅하고 싶다면, multi set을 활용할 수 있습니다.
MSET [key1] [value1] [key2] [value2] [key3] [value3] ...
Bash
복사
MGET
여러 key를 동시에 가져오고 싶다면, multi get을 활용할 수 있습니다.
MGET [key1] [key2] [key3] ...
Bash
복사
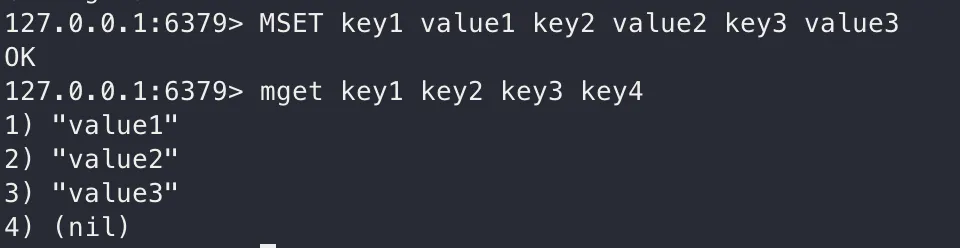
mset, mget
EXISTS
value의 존재 여부를 확인합니다. 있으면 1, 없으면 0을 반환합니다. (여러 인자를 준 경우 존재하는 개수를 반환)
EXIST [key1] [key2] ...
Bash
복사
DEL
해당 key를 삭제합니다. (값이 있어서) 삭제에 성공했으면 1, (값이 없어서) 삭제에 실패하면 0을 반환합니다.
DEL [key1] [key2] ...
Bash
복사
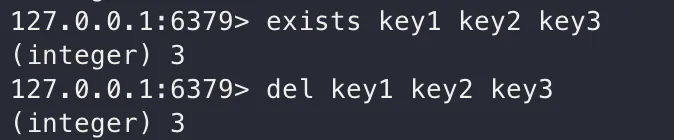
exists, del 여러 인자로!
EXPIRE
TTL 설정입니다. 단위는 초 입니다.
EXPIRE [keyName] 5(초단위)
Bash
복사
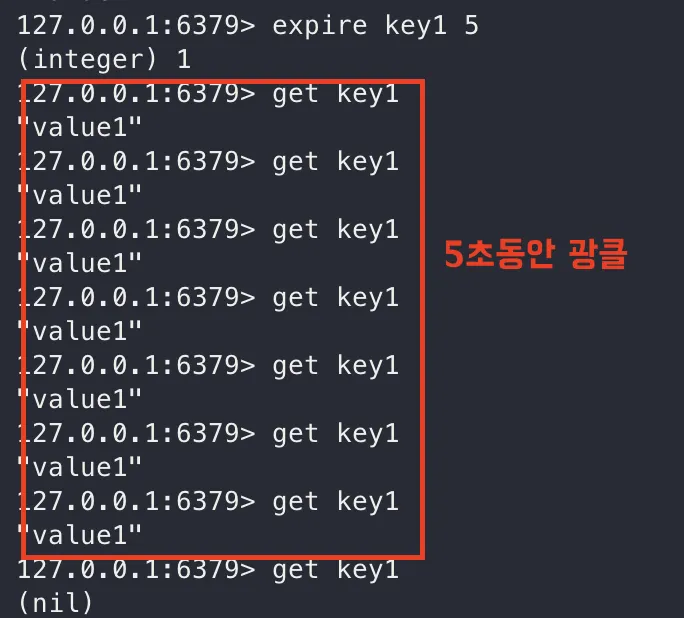
HSET
해쉬화 된 키 값에 FIELD / VALUE 쌍을 넣을 수 있습니다. field & value가 한 개 일 때는 시간 복잡도가 O(1)이지만, field & value 쌍이 늘어날 수록 O(N) (N은 쌍의 개수)으로 증가하게 됩니다.
HSET key field value [field value ...]
Bash
복사

HGET, HMGET, HGETALL, HVALS
해쉬화 된 키에 저장된 FIELD / VALUE 쌍을 찾아오는 문법입니다.
HGET은 단 건, HMGET은 다 건, HGETALL 및 HVALS은 모든 건입니다. HGETALL 같은 경우 FIELD, VALUE 순서로, HVALS는 값만 출력됩니다.
HGET key field
HMGET key field [field ...]
HGETALL key
HVALS key
Bash
복사
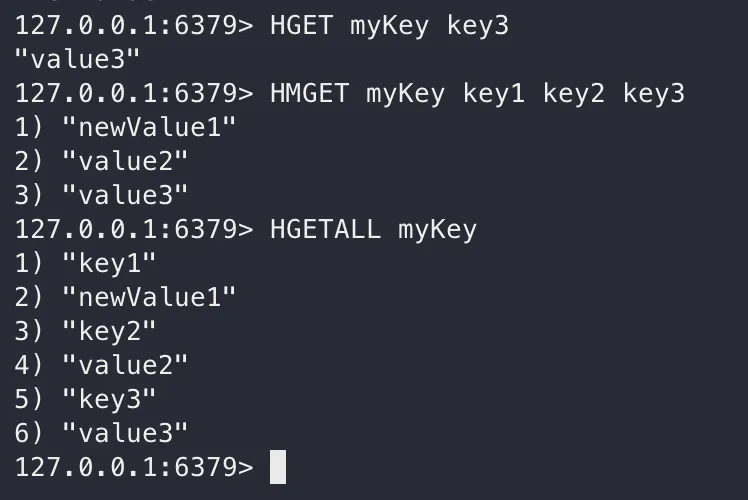
마무리
레디스와 활용 이유에 대해 간략하게 알아보고, 기본적인 설치와 활용할 수 있는 명령어에 대해서 알아보았습니다. 다음 포스팅은 레디스의 값으로 들어갈 수 있는 자료구조에 대해 알아보겠습니다~~!
레퍼런스
레디스 공식 홈페이지 https://redis.com/
NHN의 훌륭한 레디스 입문 연재 https://meetup.toast.com/posts/224
