Elasticsearch란
엘라스틱 서치는 아파치 루씬을 기반으로 한 텍스트, 숫자, 위치 기반 정보, 정형 및 비정형 데이터 등 모든 유형의 데이터를 위한 무료 검색 및 분석 엔진입니다. 텍스트 분석에 특화되어 있으며, 웹 검색 엔진에서 주로 사용 됩니다. 데이터 수집, 보강, 저장, 분석, 시각화를 위한 무료 개방형 도구 모음으로 유명한 ELK 스택(Elasticsearch, Logstash, Kibana) 중 분석과 저장을 담당합니다!

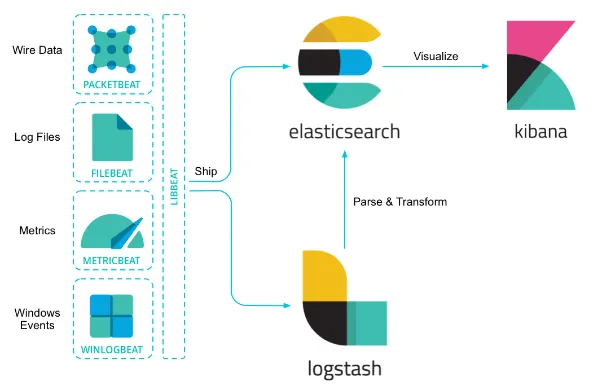
ELK 스택의 역할분담. 이 중 엘라스틱 서치는 분석과 저장을 담당합니다.
Elasticsearch를 언제 사용할까요?
ES는 다양한 분야에 활용됩니다.
1.
어플리케이션 검색
2.
로깅과 로그 분석
3.
인프라 메트릭과 컨테이너 모니터링
4.
어플리케이션 성능 모니터링
5.
위치 기반 정보 데이터 분석 및 시각화
6.
보안 분석
7.
비즈니스 분석
이 중 제가 중점적으로 여기는 부분은 어플리케이션 검색입니다. 기존 RDBMS 기반의 어플리케이션은 텍스트 검색이 어렵습니다. like 검색에 의존해야 하는데 like 검색은 동의어나 유의어에 대해선 지원해주지 않습니다. ES의 여러 특징으로 인해 문자열에 대한 동의, 유의, 전문검색 등을 지원합니다.
1.
전문 검색(Full Text Search) : 내용 전체를 색인해서 특정 단어가 포함된 문서를 검색할 수 있습니다.
2.
스키마리스 : 미리 정의된 스키마가 없어도 데이터를 스스로 분석하여 필드를 생성하고 저장합니다.
3.
RESTful api : GET, POST, DELETE 등의 REST api를 통해 데이터를 CRUD 할 수 있습니다.
4.
역색인 구조(Inverted Index) : 색인되어 있는 데이터에 대해서 문서 페이지에 대한 링크를 제공합니다.
원리는 알아보았는데 실제로 어떤 방식의 쿼리를 날리고 동작할까요?? 엘라스틱서치만의 특별한 동작 방식과 RDBMS의 SQL과는 다소 다른 쿼리들을 제공합니다. 함께 알아볼까요??
동작 원리
문서 저장
엘라스틱 서치에 index(RDMBS의 인덱스와 다릅니다)라고 부르는 데이터베이스에 문서를 저장하면 메타데이터(문서의 내부 식별자, 버전 등)와 소스 데이터(문자열)를 key-value형태의 JSON으로 변형하여 저장합니다. 저장한 각 문서를 document 라고 부릅니다. _doc api를 통해 단일데이터의 CRUD를 진행할 수 있습니다.
등록
조회
여기까진 JSON 기반의 NoSQL과 다르지 않습니다. 하지만 유의어, 동의어, 전문검색을 하기 위해 텍스트 형태의 데이터를 받아 형태소 분할을 합니다. 단어 단위로 자르고 조사는 삭제하면, 문서별로 의미있는 데이터만 추출할 수 있고, 이것을 기반으로 특정 검색어에 대해 유사도 점수를 부여하여 검색한 것과 가장 가까운 문서를 찾을 수 있습니다.
단순 텍스트 형태의 메시지를 Tokenizer, Filter 혹은 Analyzer를 통해 분할하여 저장하게 됩니다.
어떤식으로 형태소 분할을 하는지는 _analyze api을 통해 확인할 수 있습니다.
분석
이렇게 형태소 분석을 마친 데이터는 어디에 저장을 하게 될까요? 검색을 빠르게 하기 위해 역색인 자료구조에 저장합니다.
검색을 빠르게 하기 위한 역색인(inverted index) 구조
역 색인 구조에 대한 이해를 위해 하나의 문장을 추가로 삽입하겠습니다.
POST /my_index/_doc/1
{"message":"wedge potato so yammy"}
JSON
복사
POST /my_index/_doc/2
{"message":"potato better than sweet potato"}
JSON
복사
해당 문장은 그대로 저장됨과 동시에, 텍스트 타입은 형태소 분석되어 역색인(inverted index) 이라는 특별한 자료구조에 저장됩니다. 해당 자료구조엔 특정한 토큰이 어떤 문서와 연관있는지 맵핑되어 있습니다. (숫자 및 지리 필드는 BKD 트리라는 자료구조에 저장됩니다.)
Term | id |
potato | 1,2 |
wedge | 1 |
better | 2 |
... |
데이터마다 특화된 자료구조를 통해 검색 결과를 조회하고 집계하고 반환할 때 우수한 성능을 보일 수 있습니다. 검색 예시를 하나 보겠습니다. 전문 검색을 이용할 땐 _search api를 이용합니다. 간단하게 potato와 일치하는 문서를 조회하는 쿼리를 보내보겠습니다.
조회
potato가 두 번 포함되어 있던 2번 Document가 우선 검색되는 걸 볼 수 있습니다. 이는 검색어와의 유사도를 0~1 사이인 score로 표현하고, 이에 따라 내림차순 정렬한 결과입니다.
텍스트를 분석해주는 Analyzer
문자열 필드가 저장될 때 데이터에서 검색어 토큰을 저장하기 위해 여러 단계의 처리 과정을 거칩니다. 이 전체 과정을 텍스트 분석(Text Analysis) 이라고 하고 이 과정을 처리하는 기능을 애널라이저(Analyzer) 라고 합니다. Elasticsearch의 애널라이저는 0~3개의 캐릭터 필터(Character Filter)와 1개의 토크나이저(Tokenizer), 그리고 0~n개의 토큰 필터(Token Filter)로 이루어집니다.
케릭터 필터
케릭터 필터는 HTML Strip처럼 분석기가 인식할 수 있는 문자열로 바꾸어주는 역할을 합니다. 예컨데 를 white space로 바꾸어주는 작업처럼요!
Analyzer의 동작은 _analyze 를 통해 확인할 수 있습니다.
케릭터필터 예시
이 밖에도 특정 문자열을 다른 문자열로 치환해주는 Mapping 케릭터 필터, 정규 표현식을 활용할 수 있는 Pattern Replace 케릭터 필터 등이 있습니다.
토크나이저
토크나이저는 문자열 분석의 핵심입니다. 문장을 특정 단위로 잘라 각 토큰인 텀(Term)으로 만들어주는 도구로, Analyzer에 단 하나만 사용이 가능합니다. 가장 흔히 쓰는 공백을 기준으로 토큰화하는 Standard부터, 이메일과 URL도 토큰화 하는 UAX URL Email 토크나이저, 특수한 문자를 구분자로 사용하는 Pattern 토크나이저, 하이라키 형식의 문자열이 들어올 경우 하이라키를 따로 저장하는 Path Hierarchy 토크나이저 등이 있습니다. 알맞은 토크나이저를 사용하지 않으면, 예컨데 fjzjqhdl@gmail.com을 fjzjqhdl, gmail, com 단위로 분할하여 저장했다면 fjzjqhdl@gmail.com 으로 검색했을 때 알맞은 결과가 나오지 않을 수 있으므로 알맞은 토크나이저를 선정하는 것이 중요합니다.
Standard 토크나이저를 활용했을 때
URX URL Email 토크나이저를 활용했을 때
토큰 필터
토크나이저에 의해 분할된 각각의 텀들을 지정한 규칙에 따라 처리해주는 도구를 토큰 필터라고 합니다. lower case, upper case, stop(불용어), synonym(동의어), unique, Ngram(단어를 더 잘게 쪼개어 분석) 등이 있습니다.
lower case를 활용하는 예시
# Request
GET _analyze
{
"filter": [ "lowercase" ],
"text": [ "Harry Potter and the Philosopher's Stone" ]
}
JSON
복사
# Response
{
"tokens" : [
{
"token" : "harry potter and the philosopher's stone",
"start_offset" : 0,
"end_offset" : 40,
"type" : "word",
"position" : 0
}
]
}
JSON
복사
형태소 분석 - Stemming
영어를 생각하면 ~ing, ~ed 같은 변형이 있죠. 검색 시엔 이 같은 변형과 상관없이 검색이 가능해야 하기 때문에 각각의 텀에서 어간 추출 또는 형태소 분석 이필요하게 됩니다. 영어로는 stemming 이라고 합니다. 그리고 이 같은 도구를 Stemmer라고 부르는데, 영어는 Snowball, 한국어는 Nori라는 형태소 분석기가 제공됩니다. Nori 플러그인은 따로 설치를 진행해야하며, 설치시 nori_tokenizer 토크나이저와 nori_part_of_speech, nori_readingform 토큰 필터를 제공합니다.
Standard를 사용했을 때
Nori-tokenizer를 사용했을 때
마치며
엘라스틱서치의 기본 개념과 동작 원리에 대해 알아봤습니다! 다음편엔 리눅스 환경에 엘라스틱서치를 구성하는 방법, 그리고 Spring Boot와 연동하는 방법에 대해 알아보겠습니다. 감사합니다 
