글을 들어가기에 앞서
개념편에서 익힌 논 클러스티드 인덱스를 실제로 적용해보는 편입니다. 이하 인덱스라고 하면 별도의 언급이 없는 경우, 논 클러스티드 인덱스를 뜻합니다.
예제 데이터소스는 도커를 이용하니 도커 설치가 선행되어 있어야 합니다!
도커에 대해 잘 모르시는 분들은 도커 입문 수업으로 생활코딩을 추천해드리겠습니다 :)

MySQL 버전은 5.7버전, inno DB에서 진행했습니다. 버전별로 옵티마이저 로직이 다를 수 있으므로 실습의 출력결과가 직접 하시는 것과 다를 수 있습니다. 작은 규모의 데이터로 하는 실습이기 때문에 튜닝 전 실행시간이 문제 없는 걸로 보일 수 있습니다. 하지만 대규모 데이터 환경에서라면 충분히 체감할 수 있는 방향으로 진행됩니다!
실습환경 세팅
docker run -d -p 23306:3306 brainbackdoor/data-tuning:0.0.1
Shell
복사
위 내용은 -d, 컨테이너가 데몬으로 동작하고 -p, 포트바인딩(컨테이너 내부 포트와 호스트 PC의 포트를 연결하는 일)을 통해 컨테이너 내부 3306(mysql 기본포트)포트를 내 PC의 23306포트로 접근할 수 있도록 하겠다는 의미입니다. 실행할 프로세스에 해당하는 이미지는 brainbackdoor/data-tuning:0.0.1 를 사용합니다.
로그인 아이디는 user , 비밀번호는 password 입니다.
예제 소스를 활용할 수 있게 해준 CU(이동규) 코치님께 감사를 전합니다  예제 소스의 내용은 업무에 바로 쓰는 SQL 튜닝 : 최적의 성능을 위한 MySQL/MaraiDB 쿼리 작성과 튜닝실습 책의 데이터와 동일합니다!
예제 소스의 내용은 업무에 바로 쓰는 SQL 튜닝 : 최적의 성능을 위한 MySQL/MaraiDB 쿼리 작성과 튜닝실습 책의 데이터와 동일합니다!
예제 소스의 내용은 업무에 바로 쓰는 SQL 튜닝 : 최적의 성능을 위한 MySQL/MaraiDB 쿼리 작성과 튜닝실습 책의 데이터와 동일합니다!인덱스를 적용하기에 앞서
먼저 어떤 상황에서 인덱스 적용이 필요할까요?
인덱스는 조회성능 개선을 위한 것이므로 먼저 문제가 생길 수 있는 데이터를 확인해야 합니다. 현실적으로 100만건 이하의 데이터에선 인덱스로 인한 조회성능 개선 효과를 보기 어렵다고 알려져 있습니다.
순서 | 1 | 2 | 3 |
해야할 일 | SQL문 실행결과 확인 | 현황 파악 | 튜닝판단 파악 & 개선 / 적용 |
내용 | 결과 및 소요시간 확인
쿼리문 확인 | 가시적인 내용 :
- 테이블의 데이터 건수
- SELECT 절 컬럼 분석
- 조건절 컬럼 분석
- 그룹핑 / 정렬 컬럼
비가시적인 내용 :
- 실행계획
- 인덱스 현황
- 데이터 변경 추이
- 업무적 특징 | - 쿼리 튜닝
- 인덱스 설정
- 스케일업 & 스케일 아웃 |
먼저 쿼리에서 잘못 된 join을 건 부분은 없는지, PK로 검색할 수 있는 검색조건을 다르게 잡았다던지 하는 쿼리 개선사항을 확인하고 이후에 인덱스를 고려하는게 더 좋다고 생각합니다.
인덱스의 트레이드 오프
인덱스는 추가/수정/삭제에 대한 부하를 증가시키고, 별도 저장공간을 필요로 하며, 인덱스에 대한 관리 요소가 추가되기 때문입니다.
그러나 대용량 데이터에선 인덱스 없이 순수 쿼리 개선으로 성능을 개선하기엔 한계가 있기 때문에, 충분히 쿼리에 대한 최적화가 되었다면 인덱스 적용을 고려해볼 수 있습니다.
인덱스 적용해보기!
DB 세팅이 끝났다면, 워크 벤치를 실행해 접속하도록 합시다. 새로운 커넥션 생성하기를 눌러 커넥션 이름, 포트번호, 유저네임과 패스워드 (id : user, pw: password)를 입력합니다.
주의 : 포스팅을 작성할 당시 m1 실리콘 칩을 사용하는 맥북 기종 - MacBook Air (m1, 2020)에서는 도커로 띄운 DB의 조회 성능이 매우 저조하게 나오는 이슈가 있었습니다.(온프레미스 환경은 괜찮구요!) RC2 버전을 설치하면 해결된다는 이슈도 있지만, 도커 버전 문제인지 제 PC에선 매우 느린 상태입니다. 조회 속도가 포스팅에 비해 너무 빠르셔도 놀라지 마셔요!
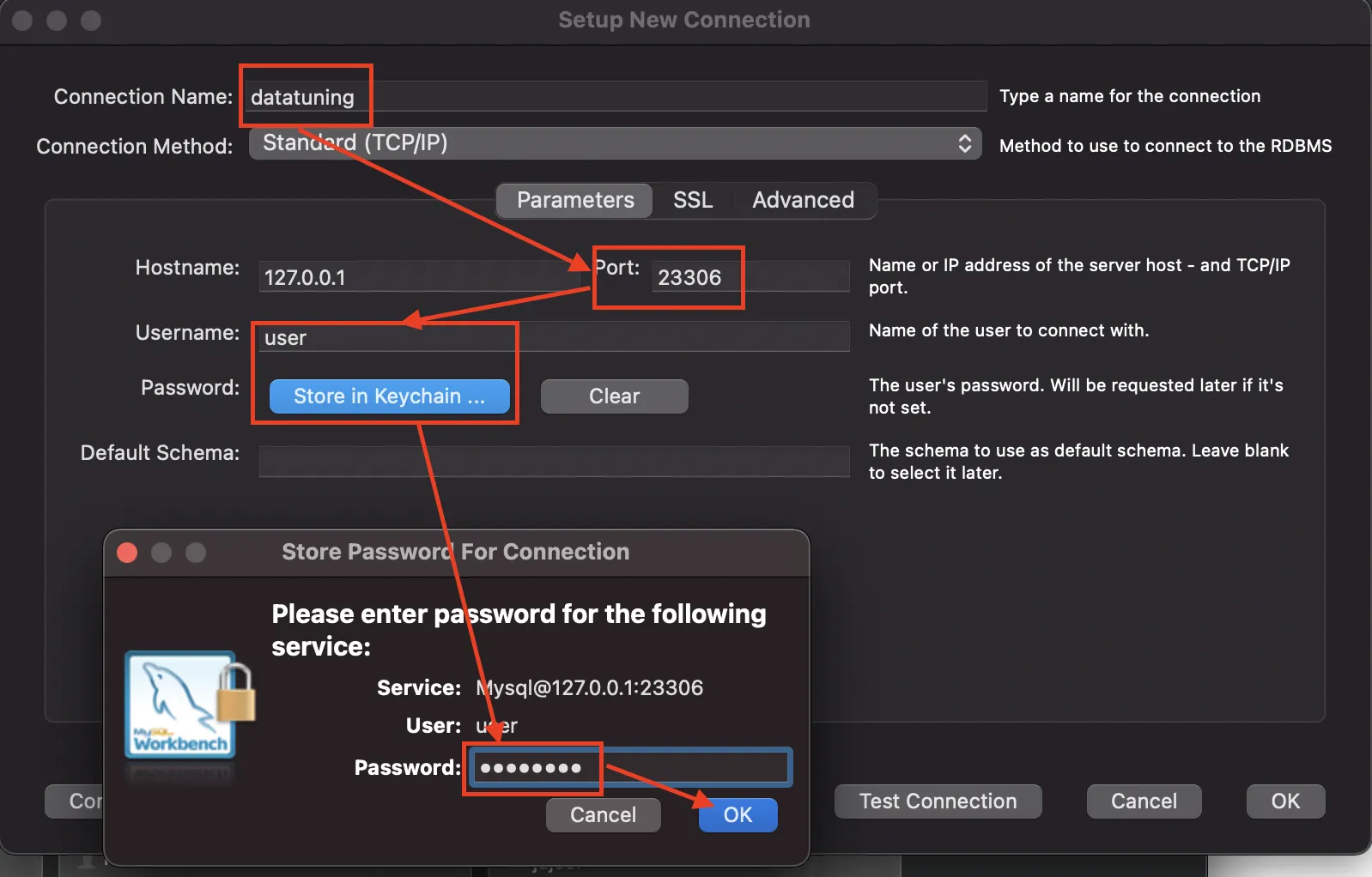
23306에 바인딩 했기 때문에, 23306포트로 접속하면 됩니다.
접속이 끝났다면, use tuning; 쿼리를 통해 tuning 데이터베이스를 이용합니다.

인덱스를 적용을 고려할 수 있는 칼럼은 자주 범위 조건으로 조회되는 칼럼, 정렬 및 그룹핑 순서로 자주 이용되는 칼럼, 조인에 사용되는 칼럼입니다.
PK(기본키) 같은 경우는 클러스티드 인덱스로 설정되기에 따로 인덱스를 잡아 줄 필요가 없습니다. FK(외래키) 같은 경우 자동으로 논클러스티드 인덱스로 등록됩니다. 그러므로 PK와 FK가 아니면서 조회절에 자주 이용되는 칼럼을 인덱스로 고려하시면 됩니다. 다만 개념편에서 확인하셨듯이 인덱스 테이블은 B Tree 자료구조이기 때문에, 데이터 중복도가 높은(카디널리티가 낮은) 칼럼이라면 인덱스의 효과를 제대로 보기 어려울 수 있습니다.
예제 - Georgi Wileonsky 사원 조회하기
인덱스 없이 조회하기
select *
from 사원
where 이름 = 'Georgi' and 성 = 'Wielonsky'
SQL
복사
다음 쿼리를 조회해보겠습니다.
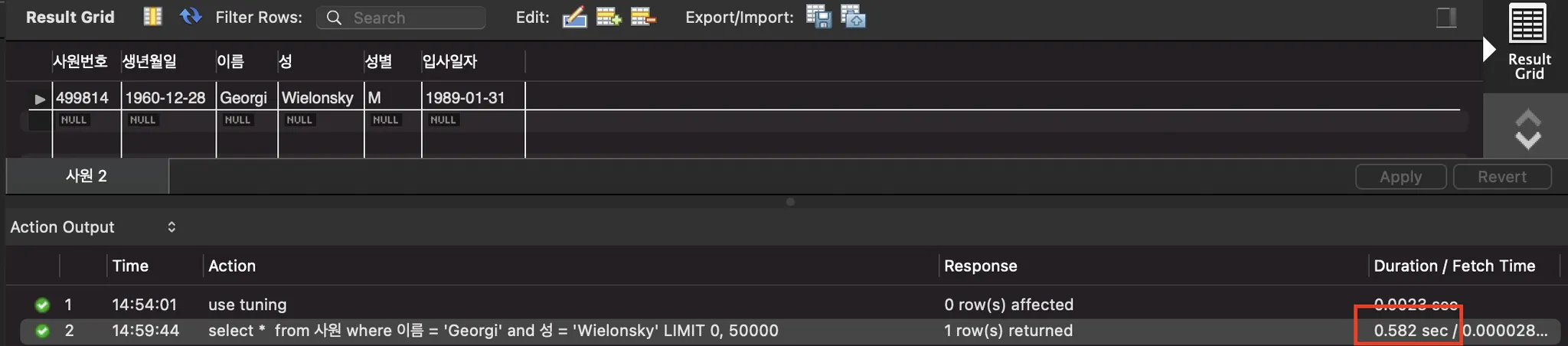
데이터는 단 건, 조회 속도는 0.582 sec입니다.
인덱스 없이 조회하기 - 실행계획
explain 키워드를 조회쿼리 앞에 붙여 재조회 해보면 다음과 같은 결과를 얻을 수 있습니다.
explain select *
from 사원
where 이름 = 'Georgi' and 성 = 'Wielonsky'
SQL
복사

풀 테이블 스캔을 하고 있네요! 최종 조회결과는 1건 인데, 이를 찾아오기 위해 전체 테이블을 조회하고 있으므로 비효율적이라고 판단할 수 있습니다. 이런 경우 이름과 성으로 이루어진 복합 인덱스를 고려해볼 수 있는데요, 복합 인덱스를 적용할 경우 순서에 주의하여야 합니다.
복합 인덱스의 구조
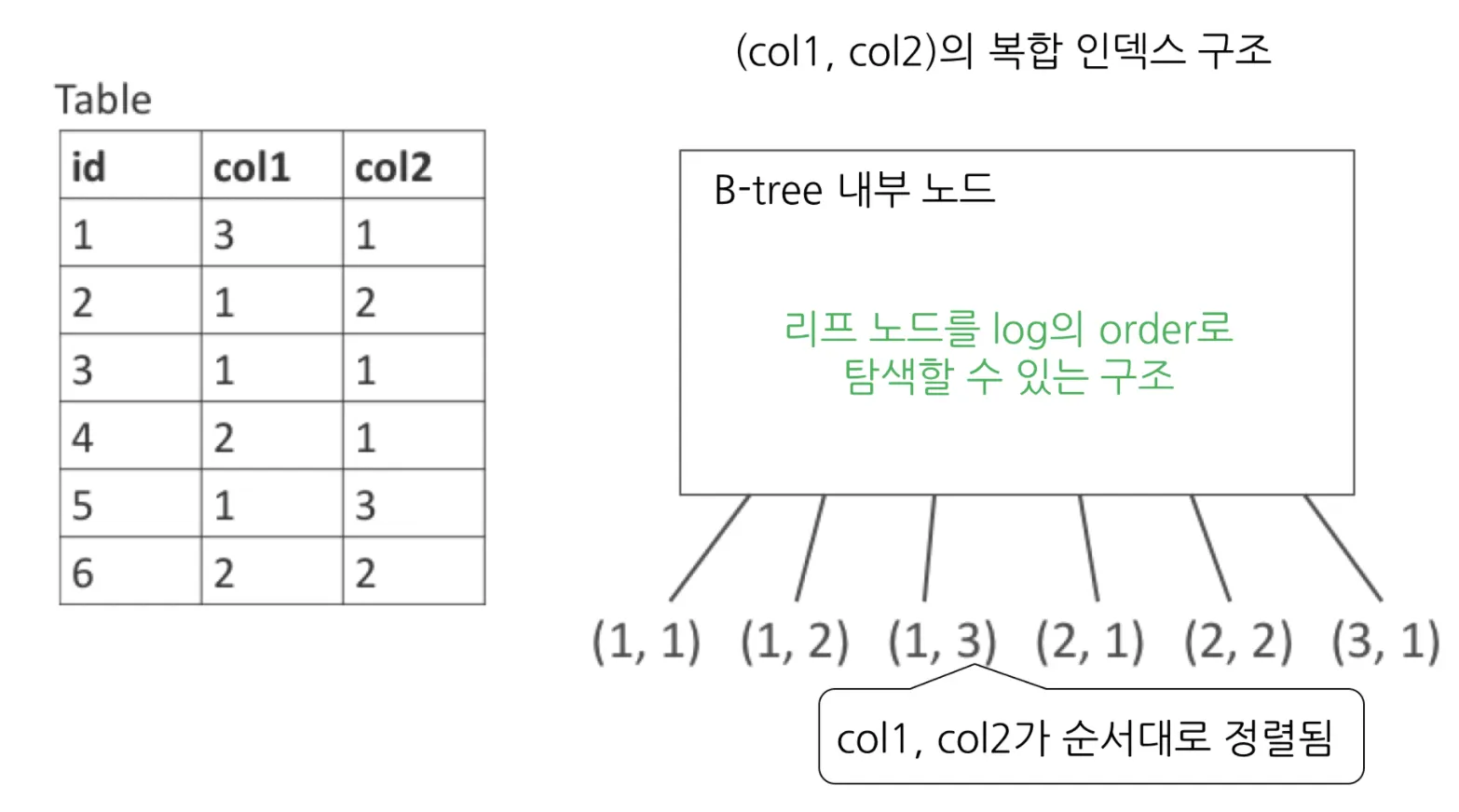
라인 엔지니어링 개발블로그에서 가져온 이미지입니다! 링크
복합 인덱스는 다음처럼 지정한 컬럼순으로 정렬되기 때문에 (col1 먼저 정렬하고 각 col1에 대해 col2 정렬), 선두 컬럼을 어떤 것으로 결정하느냐에 따라 성능 차이를 보입니다. 선두 컬럼의 중복도가 낮을수록 먼저 찾아야 하는 데이터의 모수를 줄이고 갈 수 있기 때문에 선두 컬럼의 중복도가 더 낮은 걸 선택하는 것이 효율적입니다.
하지만 범위 검색을 하는 칼럼이 있는 상황이라면 상황이라면, 범위검색을 하는 칼럼을 뒤에 두어주세요.
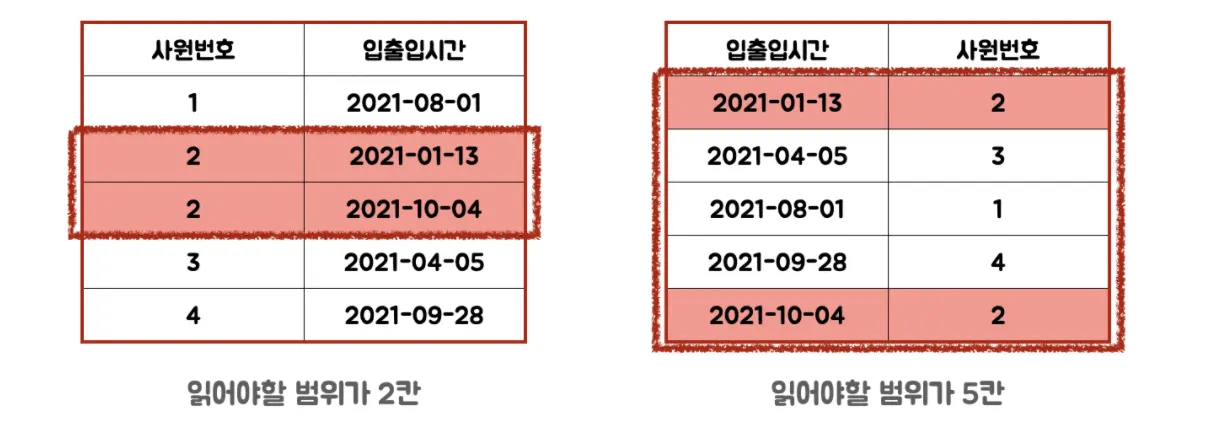
선두 칼럼이 범위검색을 하는 경우, 두번째 인덱스 칼럼을 제대로 활용 못하기 때문입니다. 자세히 알고 싶으시다면 아래 내용을 읽어보셔요! 일본어지만 구글번역이 모든 걸 해결해 준답니다 하하 구글 만세
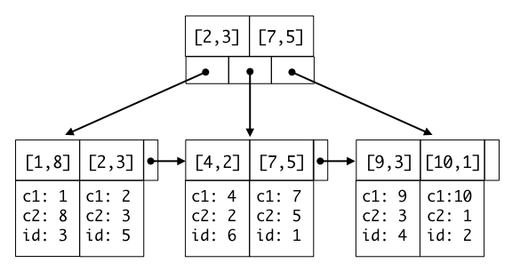
인덱스 설정하기
위 예제의 인덱스를 잡기 위해 이름 칼럼과 성 칼럼의 개수를 확인해 보겠습니다.
select
count(DISTINCT(이름)) 이름_개수,
count(DISTINCT(성)) 성_개수,
count(1) 전체
from 사원;
SQL
복사
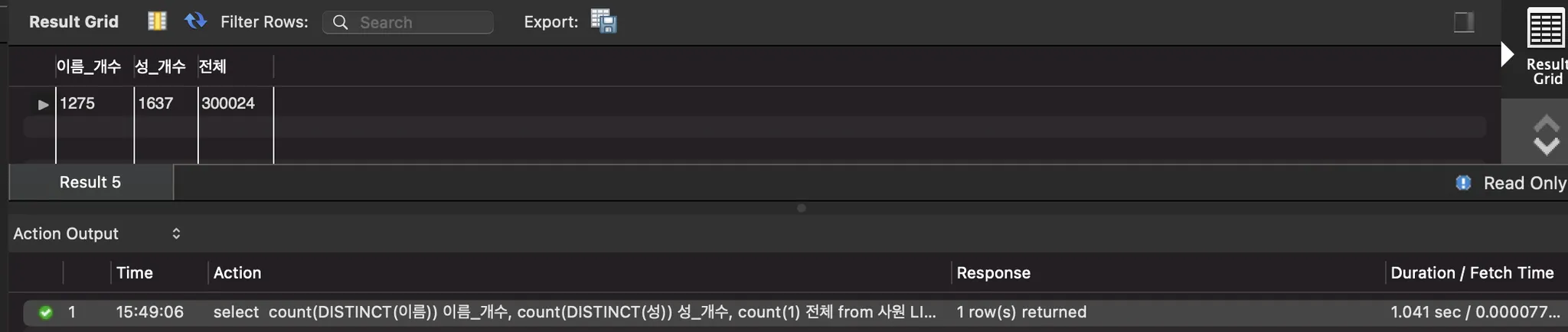
이름은 1275개, 성은 1637개 이므로 이름의 중복도가 더 낮습니다.
그러므로 성을 선두 칼럼으로, 이름을 후위 칼럼으로 두어 복합 인덱스를 설정해 보겠습니다.
alter table 사원 add index I_사원_성_이름 (성, 이름);
SQL
복사
이미 데이터가 많은 테이블이라면 인덱스 테이블을 생성하기 위한 시간이 오래 걸릴 수 도 있습니다!

적용이 완료되었네요, 다시 쿼리를 실행해 결과를 확인해 보겠습니다.
인덱스를 적용한 후 조회하기
select *
from 사원
where 이름 = 'Georgi' and 성 = 'Wielonsky'
SQL
복사
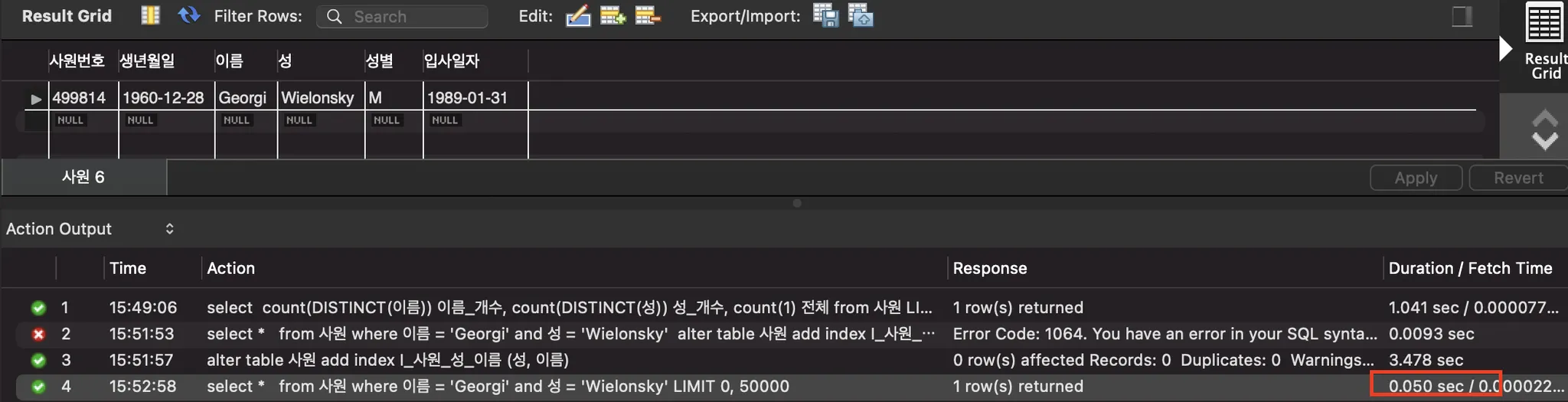
0.582s → 0.05s 로 100배 성능이 향상되었네요~~! 짝짝짝
인덱스 없이 조회하기 - 실행계획
실행 계획은 어떻게 되었을까요?
explain select *
from 사원
where 이름 = 'Georgi' and 성 = 'Wielonsky'
SQL
복사

인덱스 검색을 통해 1건의 데이터를 조회했습니다. 30만건 전체를 검색해야 했던 풀테이블 스캔과는 대조적이네요.
이제 인덱스 활용 시 주의사항을 알아보며 글을 마무리 하겠습니다!
주의사항
인덱스 컬럼을 가공하지 마세요!
EXPLAIN
SELECT *
FROM 사원
WHERE SUBSTRING(사원번호, 1, 4) = 1100
AND LENGTH(사원번호) = 5
SQL
복사
EXPLAIN
SELECT *
FROM 사원
WHERE 사원번호 BETWEEN 11000 AND 11009
SQL
복사
•
인덱스 컬럼을 가공하지 않아야 합니다! 인덱스 칼럼을 가공하면 제대로 된 결과를 얻을 수 없습니다.
◦
<>, NOT IN, NOT BETWEEN과 같은 NOT-EQUAL로 비교된 경우
◦
LIKE '%??'
◦
SUBSTRING(column, 1, 1), DAYOFMONTH(coulmn)과 같이 인덱스 칼럼이 변형된 경우
◦
WHERE char_column = 10 과 같이 데이터 타입이 다른 비교
인덱스 순서를 고려하세요!
EXPLAIN
SELECT 성, 성별, COUNT(1) AS 카운트
FROM 사원
GROUP BY 성, 성별 // 성을 먼저, 성별을 나중에
SQL
복사
EXPLAIN
SELECT 성, 성별, COUNT(1) AS 카운트
FROM 사원
GROUP BY 성별, 성 // 성별을 먼저, 성을 나중에
SQL
복사
•
인덱스는 항상 정렬 상태를 유지하므로 인덱스 순서에 따라 ORDER BY, GROUP BY를 위한 소트 연산을 생략할 수 있습니다.
•
조건절에 항상 사용하거나, 자주 사용하는 컬럼을 인덱스로 선정합니다.
•
'=' 조건으로 자주 조회하는 컬럼을 앞쪽에 둡니다.
•
추가적으로, 아래 세 인덱스는 중복입니다. 마지막 인덱스를 남기고 모두 삭제해주세요.
◦
과세코드
◦
과세코드 + 이름
◦
과세코드 + 이름 + 연령
위와 같이 3개의 인덱스가 있는 것이 과세코드 조회 시 조회성능은 더 잘 나올 수 있지만, 인덱스는 트레이드오프가 있음을 항상 기억하세요!
Covered Index를 활용할 수 있다면 활용하세요!
커버드 인덱스는 인덱스 스캔과정에서 얻은 정보만으로 처리할 수 있어 테이블 액세스가 발생하지 않는 쿼리를 의미합니다.
EXPLAIN SELECT a.*
FROM (
-- 서브쿼리에서 커버링 인덱스로만 데이터 조건과 select column을 지정하여 조인SELECT id
FROM subway.member
WHERE age BETWEEN 30 AND 39
) AS b JOIN programmer a ON b.id = a.id
SQL
복사
디스크에 대한 IO가 발생하지 않기 때문에 매우 빠른 조회성능을 보입니다.
직접 해보기
우아한테크코스 3기 강의내용에선 직접 해보기로 다음과 같은 내용이 있었는데, 위 내용을 적용해서 직접 해보시는 것도 재밌을 것 같아요
요구사항
1. 쿼리 작성만으로 1s 이하로 반환한다.
2. 인덱스 설정을 추가하여 50 ms 이하로 반환한다.
•
활동중인(Active) 부서의 현재 부서관리자 중 연봉 상위 5위안에 드는 사람들이 최근에 각 지역별로 언제 퇴실했는지 조회해보세요.(사원번호, 이름, 연봉, 직급명, 지역, 입출입구분, 입출입시간)
•
급여 테이블의 사용여부 필드는 사용하지 않습니다. 현재 근무중인지 여부는 종료일자 필드로 판단해주세요. (9999-01-01)
당시 m1 도커 DB에서 조회가 느리다는 걸 몰라 많은 시행착오를 겪었는데, 당시의 고민은 아래 링크에 남아있습니다
실습테이블 정보
실습 테이블 구조와 칼럼
1.
사원 테이블 - 직원 들의 정보
a.
사원번호 : 사원이라는 오브젝트를 유일하게 구분할 수 있는 숫자
b.
생년월일 : 해당 사원의 년/월/일을 날짜 타입으로 구성
c.
이름 : 사원의 이름
d.
성 : 사원의 성(Family name)
e.
성별 : 사원의 성별 정보. M과 F 라는 데이터만 입력할 수 있음
f.
입사일자 : 사원이 해당 기업에 입사한 날짜
2.
부서 테이블 - 업무 부서
a.
부서번호 : 부서를 유일하게 식별할 수 있는 숫자
b.
부서명 : 부서 이름
c.
비고 : 해당 부서가 현재 유효한지를 나타내는 정보로 NULL값이 포함될 수 있음
3.
부서사원_매핑 테이블 - 부서 테이블과 사원 테이블의 매핑정보를 담고 있음
a.
사원번호 : 사원을 유일하게 식별할 수 있는 숫자
b.
부서번호 : 부서를 유일하게 식별할 수 있는 숫자
c.
시작일자 : 사원이 해당 부서에 소속된 일자
d.
종료일자 : 사원이 해당 부서에 소속 해지된 일자
4.
부서관리자 테이블 - 부서를 대표하는 관리자 사원의 정보가 저장되는 테이블
a.
사원번호 : 관리자에 해당하는 사원번호
b.
부서번호 : 부서를 유일하게 식별할 수 있는 숫자
c.
시작일자 : 해당 부서에 사원이 관리자 역할로 임명된 일자
d.
종료일자 : 해당 부서에 사원이 관리자 역할에서 해지된 일자
5.
직급 테이블 - 사원이 위치한 직급의 히스토리
a.
사원번호 : 사원을 유일하게 식별할 수 있는 숫자
b.
직급명 : 사원이 위치한 포지션
c.
시작일자 : 해당 직급이 부여된 일자
d.
종료일자 : 해당 직급이 만료된 일자로, NULL 일 때는 종료일자가 정해지지 않았음을 의미
6.
급여 테이블 - 사원별로 매년 계약한 연봉 정보의 히스토리
a.
사원번호 : 사원을 유일하게 식별하는 숫자
b.
연봉 : 계약된 연봉 숫자
c.
시작일자 : 해당 연봉 정보가 유효한 시작 일자
d.
종료일자 : 해당 연봉 정보가 만료되는 일자
e.
사용여부 : 해당 연봉정보의 활성화 여부를 나타내는 문자로서 NULL 값이 포함될 수 있음
7.
사원 출입기록 테이블 - 지역별, 출입문별로 출입한 이력에 관한 시간 정보를 적재하는 테이블.
a.
순번 : 자동으로 숫자가 증가하는 시퀀스
b.
사원번호 : 사원을 유일하게 식별하는 숫자
c.
입출입시간 : 출입한 시간정보로 TIMESTAMP 형식으로 적재됨
d.
입출입구분 : 출입의 구분자를 I와 O라는 문자로 저장
e.
출입문 : 출입문 코드로 NULL이 포함될 수 있음
f.
지역 : 지역 코드로 NULL이 포함될 수 잇음
각 테이블별 건수

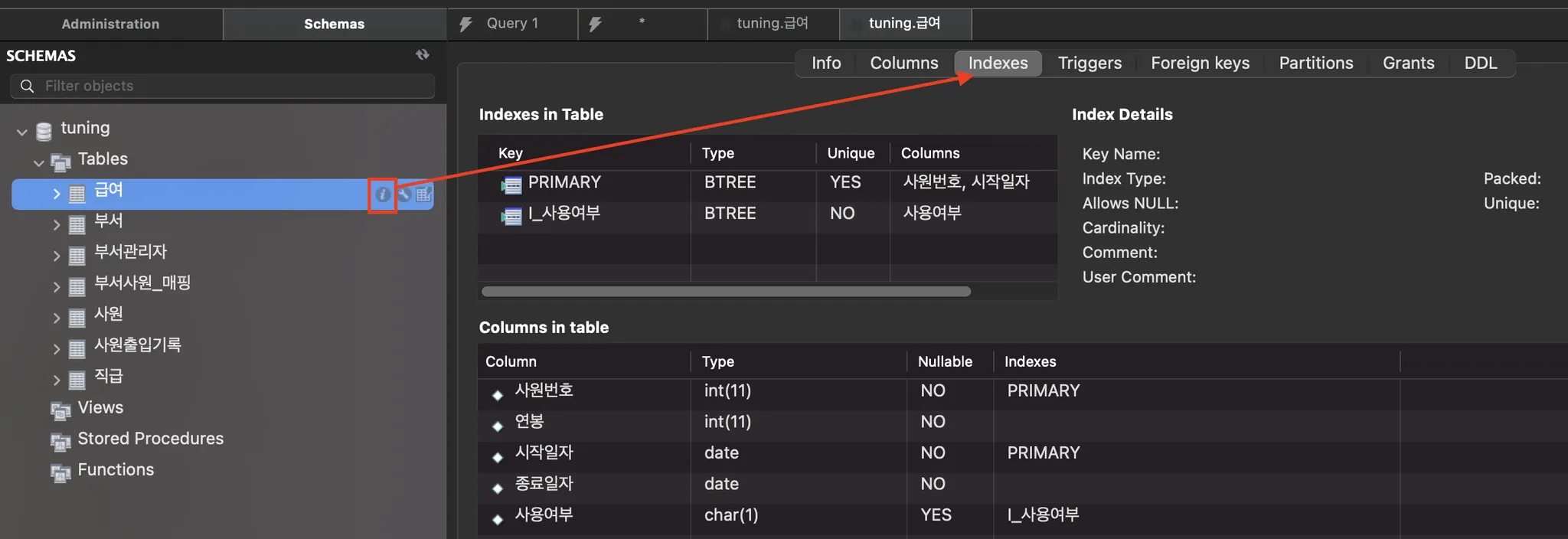
각 테이블별 인덱스
show index from %테이블% 명령어로 확인할 수 있습니다! 워크벤치라면 테이블 정보를 눌러서 확인할 수 도 있습니다.